

I’m going to talk about a technique I picked up that I’ve never seen done anywhere except for where I currently work. Because I’ve been programming professionally for over a decade and this is the first time I’ve seen this, I figure it must be relatively unfamiliar to others. This is a technique I’ve been calling “Extreme SRP”. But before I explain what the Extreme version of SRP is, I should explain what SRP is:
SRP stands for the Single Responsibility Principle. It means that a class should only have one reason to change. If you want to learn more, this link is a good reference.
Extreme SRP, surprisingly enough, is taking SRP to the extreme. Before I talk about what it is, I want to preface the description with a suggestion: Keep an open mind. When I first saw this technique my immediate thought was, “That’s not idiomatic”. But, I went with it to see how it’d turn out. In the end I had few complaints but I thought I would have many. It’s easy to think, “That looks weird so it must be bad” but unless you try it, you don’t really know if that’s true.
I’m going to describe Extreme SRP with a set of rules:
- Every class can only have one method.
- That method must be public.
- Every field of the class must be dependency injected.
Here’s an example class following this practice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
@Component public class MiddleNode { @Autowired private EndLeaf1 endLeaf1; @Autowired private EndLeaf2 endLeaf2; public Result useEnd(String parameter) { Result result = new Result(); result.setSomething(endLeaf1.useEnd(parameter)); result.setSomethingElse(endLeaf2.useEnd2(parameter)); return result; } } |
And that’s pretty much how all the code in your code base ends looking when you practice “Extreme SRP”. This class is what I call a “node” because it’s only responsible for delegating to other nodes/leaves. Eventually it will delegate to a leaf. A leaf is a node that doesn’t delegate to other nodes. This is usually where the “meat” of your feature goes. The nodes are responsible for delegating to the leaves, translating inconvenient parameters from the outside world to convenient data that it prefers to work with.
As a result, your code base ends up looking like this:
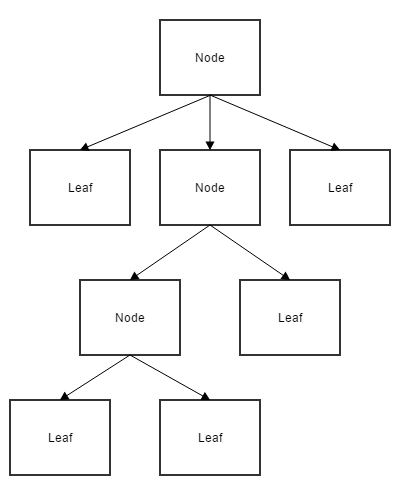
In other words, your code becomes a tree datatype.
“Extreme SRP” has all the advantages of SRP:
- Code complexity is reduced by being more explicit and straightforward
- Loose coupling
- Improved readability
The methods are very small and easy to understand. But, if you’re looking for a specific leaf and you don’t know its name, you have to traverse the tree to get there. Whereas a lot of these classes may be inlined into one method when using traditional techniques so the code would be easier to find. This is one of the downsides you have to live with when you practice “Extreme SRP”.
As I said above, this code is not very idiomatic, at least for most object oriented languages. It’s more procedural/functional in nature. But because of the rule above that says every field must be dependency injected, the entire code base is extremely easy to test. The non-idiomatic code threw me off originally, but the ease of testability makes it worth it, in my opinion.
The way you go about creating a system like this from start to finish has a lot of advantages. You think about a node and what it directly delegates to instead of the whole tree at once. How you go about thinking this was is documented in another article I wrote.
There are no cyclical dependencies where A depends on B and B depends on A. This simplifies a lot in your code base and makes it easier to modularize your code. The code base requires minimal refactoring. Usually I can throw away a node and rewrite it instead of refactoring it into what I want. Or I simply have to connect one node to a different one, etc. It requires a lot less thought and it rarely feels necessary. Whereas using traditional object oriented techniques, refactoring feels built in to the process and is the first and last step of adding a new feature.
This technique does create an explosion of classes and you have to come up with names for all of them. It’s not always easy but whenever I struggle with this I feel like there is a concept that needs to be named, I just can’t think of the name for it. It’s rarely a situation where I feel like the concept doesn’t exist.
Because of this class explosion, you have to be really good with your namespaces to organize your code. Otherwise, you’ll get lost and it’ll slow you down to browse your code base.
Other than that, I’m really happy with “Extreme SRP”. I recommend that readers put their biases aside and give it a try on your next hobby project and see how it turns out for you. I’d love to hear your feedback on how it turned out!
What would you do when get a nasty bug and you have to debug you code?
I’m not quite confidence about code complexity hope you could elaborate it more.
It looks like you are on the way to functional programming.
Rodney Brooks. No Silver Bullet.
With this approach, we have moved some complexity from logic that was contained within a small number of functions or classes to the structure and relationships that exist between some larger set of functions and classes.
If we have a really good code navigation tool that lets us visualise and navigate the relationship between classes, (i.e. the call graph) then all is well and this is a reasonable approach.
If, on the other hand, we only have a text editor, then we need to navigate from one location to another and remember things to understand what is going on. This means that we have created a (possibly significant) cognitive burden on anyone other than the original author who has to interact with the code. I.e. introduced some accidental complexity and additional maintenance cost into our system.
The trade-off (and therefore the value of this approach) is entirely dependent on the tools that you use to manage the structures and relationships wherein the bulk of your complexity is to be found.
This general principle is true if you are shifting complexity to ops (microservices) or to the relationship between functions (functional programming) or to your test data (deep learning).